神译局是36氪旗下编译团队,关注科技、商业、职场、生活等领域,重点介绍国外的新技术、新观点、新风向。
编者按:作为一个为会员提供娱乐内容的流媒体服务商,服务的稳定和流畅至关重要。但是,一旦基础设施出现中断,服务可能就会受到巨大影响。就算服务不会完全中断,但因为不断涌入的请求会将少数可用资源压垮,最终服务也会很快变得不可用。如何才能在恢复系统的同时尽量保障服务的不中断?Netflix技术团队在其官方技术博客上分享了他们的实践。原文作者Manuel Correa、Arthur Gonigberg与Daniel West。标题是:Keeping Netflix Reliable Using Prioritized Load Shedding

对于全世界的司机来说,堵车应该是最令人沮丧的经历之一了。每一辆车都慢得像蜗牛一样,有时是因为一个小问题,有时候根本就不知道怎么回事。作为Netflix的工程师,对于如何去重新设计我们的流量管理,我们一直在不断地进行评估。如果我们知道每一位旅客的紧迫性,并且可以有选择地引导汽车通过,而不是让所有人都要一起等待的话,会怎样呢?
对于Netflix的工程设计来说,我们的驱动力是在你需要的时候确保Netflix就在那里。不过,直到去年之前,我们的系统还是容易受到所谓的“交通拥堵”的影响。我们有简单粗暴的开/关断路器,但是没有逐步的负载分流手段。在改善我们会员体验的推动下,我们引入了基于优先级的逐步负载分流技术。
下面的动图展示的是,当后端根据优先级对流量进行限制时,访客的行为情况。当优先级较低的请求被限制时,回放体验仍然流畅,访客仍可以观看节目。下面我们就探讨一下我们是怎么做到这一点的。

后台在恢复的时候用户体验大部分仍不受影响
失败的发生可能有多种原因,例如:行为异常的客户端会触发重试风暴,后端的服务规模不足,部署不正确,网络出现故障或云提供商出现问题。考虑到这些事件,我们着手使Netflix在以下目标上更具弹性:
有很多原因可能会导致失败,比方说:客户端行为不当引发重试风暴,后台服务伸缩能力不足,部署不当,网络故障,或者云供应商的问题等等。所有这些故障可能会使系统承受意外负载,在过去,这些例子的每一个都曾一度让我们的会员丧失了播放的能力。为了防止此类突发事件的发生,我们开始着手让Netflix更具弹性,我们要考虑实现的目标包括:
跨设备类型(移动、浏览器和电视)一致的请求优先排序
基于优先级逐步限制请求
通过对特定优先级的请求进行混沌测试(Chaos Testing,故意注入故障)来验证假设
我们设想的考虑按优先级限流以及混沌测试的最终架构如下所示。

具备按优先级限流和混沌测试的高级回放架构
为了对请求的流量进行分类,我们决定聚焦在三个方面:吞吐量,功能性以及关键性。基于这些特征,流量可分为以下几种:
NON_CRITICAL(非关键):此类流量不会影响播放或者会员体验。此类流量的例子包括日志和后台请求。这种请求往往吞吐量很高,在系统负载来源当中占据了相当大的比例。
DEGRADED_EXPERIENCE(体验降级):这种流量会影响会员的体验,但不会影响播放的能力。这类一般用于以下功能:停止和暂停标记,播放器的语言选择,观看历史记录等。
CRITICAL(关键):此类流量会影响播放功能。如果请求失败,会员在点击播放时会看到一条错误消息。
API网关服务(Zuul )使用请求的属性将请求分类为NON_CRITICAL,DEGRADED_EXPERIENCE和CRITICAL存储桶,并根据给定的各个特征为每个请求计算1到100之间的优先级得分。计算是第一步,因此可以在请求生命周期的剩余时间内使用。
API网关服务(Zuul)会根据请求的属性,将其分为NON_CRITICAL、DEGRADED_EXPERIENCE以及CRITICAL,并根据每个请求的特征,计算其优先级得分(1到100)。计算是请求生命周期的第一步,后续步骤要用到。
大多数情况下,请求工作流程会正常进行,而不会考虑请求优先级。但是,与任何服务一样,有时我们遇到一个后端出现问题或Zuul本身出现问题的情况。当发生这种情况时,具有较高优先级的请求将得到优先处理。优先级较高的请求将得到满足,而优先级较低的请求将不会得到响应。该实现类似于具有动态优先级阈值的优先级队列。这允许Zuul丢弃优先级低于当前阈值的请求。
大多数情况下,请求工作流在不考虑请求优先级的情况下,也是可以正常运行的。不过,就像任何服务一样,有时我们也会遇到后端之一出问题或者Zuul出问题的的情况。一旦发生这种情况时,优先级更高的请求会被优先处理。优先级较高的请求会获得服务,而优先级较低的请求则不会。其实现类似于有着动态优先级阈值的优先级队列。这可以让Zuul丢弃优先级低于当前阈值的请求。
Zuul可以在请求生命周期的两个时刻应用减载:将请求路由到特定的后端服务(服务限制)时或在初始请求处理时,这会影响所有后端服务(全局限制)。
在请求的整个生命周期里,Zuul有两个时间点可以进行负载分流:一是当它将请求路由到特定的后端服务时(服务限流),二是在开始处理请求时,这会影响到所有的后端服务(全局限流)。
服务限流
Zuul可以通过监视错误率和对该服务的并发请求来感知后端服务何时出现问题。这两个指标是故障和延迟的近似指标。当超过这两个指标之一的阈值百分比时,我们将通过限制流量来减少服务负载。
通过监控错误率和对自己的并发请求量,Zuul可以觉察到服务什么时候出现了问题。这两个指标,是反映故障和延迟的大致指标,当其中一个指标超过阈值的百分之一时,我们会通过限制流量,来降低服务负载。
全局限流
另一种情况是Zuul本身出问题了。跟上面的情况相反,全局限流会影响Zuul后面所有的后端服务,而不是单个后端服务。这种全局限流的影响可能会给会员造成更大的问题。用来触发全局限流的关键指标,包括CPU利用率、并发请求数有一集连接数量,当任何一个指标超过阈值时,Zuul都会主动限制流量,从而在系统恢复的同时保持自身的正常运行。这个功能非常关键:如果Zuul出现故障,流量就不能通过我们的后端服务,从而导致服务全面中断。
设置好优先级部分后,我们便可以将其与减载机制结合起来,从而大大提高流传输的可靠性。当我们处于恶劣情况下(即超过上述任何阈值)时,我们会从最低优先级开始逐渐减少流量。三次函数用于管理节流级别。如果情况真的变得非常糟糕,那么水平将触及曲线的尖角,从而限制一切。
在确定了优先级之后,我们就可以将其跟我们的负载分流机制结合起来,从而极大提高流媒体播放的可靠性。当我们遇到糟糕情况时(也就是上述任何指标超过阈值)时,我们会从最低优先级开始,逐步丢弃流量。我们用一个三次函数来管理限流级别,如果情况变得非常非常糟糕,限流的级别就会触及曲线的尖角,限制一切流量。
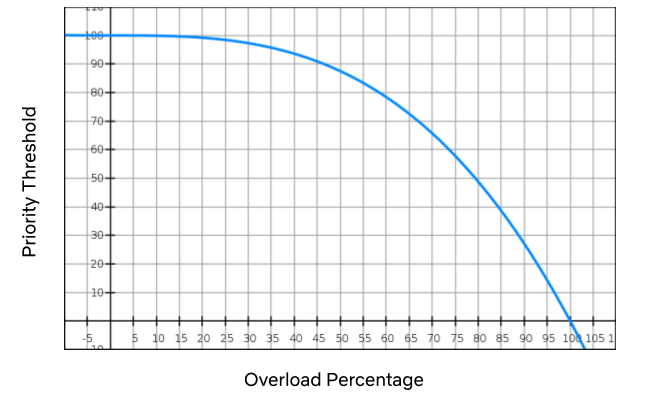
上图是如何应用三次函数的示例。随着过载百分比的增加(即节流阈值和最大容量之间的范围),优先级阈值会非常缓慢地跟踪它:在35%时,它仍处于90年代中期。如果系统继续降级,我们会以超过80%的优先级达到50,然后达到95%的优先级10,依此类推。
上图是三次函数应用的一个示例。过载百分比不断增加(即限流阈值与最大容量之比),但优先级阈值变化依然不大:过载百分比为35%时,优先级阈值仍然在90左右。如果系统还在不断降级,在过载百分比超过80%的情况下,优先级阈值仍有50,然后在过载百分比达95%的情况下优先级阈值达到10。
考虑到相对少量的请求会影响流媒体播放的可用性,限制低优先级的流量可能会影响到某些产品功能,但不会影响会员按下“播放”并观看自己喜欢的节目。通过引入基于优先级的逐步负载分流,Zuul可以卸载掉足够的流量来稳定服务,又不会引起会员的注意。
应对重试风暴
当Zuul决定放弃流量时,它会向设备发送信号,让他们知道我们需要他们退后。它通过指示可以执行多少次重试以及可以在哪种时间范围内执行来实现此目的。例如:
当Zuul决定放弃流量时,它会向设备发送信号,让对方知道我们需要它们卸载流量。Zuul会告诉设备最大的重试次数,以及可以在什么样的时间窗口下执行这些重试命令,这样就解决了重试风暴的问题。比方说:
{“maxRetries”:<max-retries>,“retryAfterSeconds”:<seconds>}
使用这种反压机制,我们可以比过去更快地停止重试风暴。我们会根据请求的优先级自动调整这两个拨盘。高优先级的请求将比低优先级的请求更积极地重试,这也提高了流式传输的可用性。
利用这种反压机制,跟过去相比,我们可以更快地停止重试风暴。我们会根据请求的优先级自动调整这两个刻度盘,高优先级的请求的重试频率会比低优先级的请求的更高,这也会提高流媒体的可用性。
为了验证关于特定请求是否属于NON_CRITICAL,DEGRADED或CRITICAL存储桶的请求分类法假设,我们需要一种方法来测试该请求发出时用户的体验。为此,我们利用了内部故障注入工具(FIT),并在Zuul中创建了一个故障注入点,该点使我们能够根据提供的优先级发出任何请求。这使我们能够手动模拟负载脱落的阻断优先级范围,特定设备或成员,让我们知道哪些要求可能是安全的,而不会影响用户体验棚。
为了对我们的请求分类假设(NON_CRITICAL、DEGRADED及CRITICAL)是否合适进行验证假设,我们需要有一种方法来测试当该请求被卸载时用户的体验。为此,我们利用了内部故障注入工具(FIT),并在Zuul中创建了一个故障注入点,这让我们可以根据提供的优先级来舍弃任何的请求。如此,我们就可以通过屏蔽特定设备或会员特定优先级范围的请求,来手动模拟负载分流体验,让我们了解哪些请求可以安全地卸载掉,而不会影响到用户。
这里的目标之一,是通过丢弃预期不会影响用户流媒体体验的请求,来减轻会员的痛苦。不过,Netflix的变化是很快的,那些被认为非关键的请求可能也会意外地变成关键请求。此外,Netflix还有多种的客户端设备、客户端版本,以及多种跟系统交互的方式。为了确保在任何情况下限制NON_CRITICAL请求时我们都不会引起成员的痛苦,我们利用了自己的基础设施试验平台ChAP。
这个平台可以让我们开展A/B测试,把我们的少量产品用户分配到对照组或实验组,每次实验45分钟的时间,同时对实验组一定范围内的优先级进行限制。这可以让我们捕捉到各种实时的用例,并衡量它们对回放体验的影响。ChAP按照设备分析每一位会员的KPI,以确定对照组和实验组之间是否存在偏差。
在我们的第一个实验里,我们在Android和iOS设备上都检测到了低优先级请求的紊乱情况,这会导致零星的播放错误。由于我们进行的是连续实验,所以一旦初始的实验开始运行,并且bug得到了修复,我们会安排实验继续按照周期运行。这样一来,我们就能够尽早检测出回归,并让用户保持正常播放。
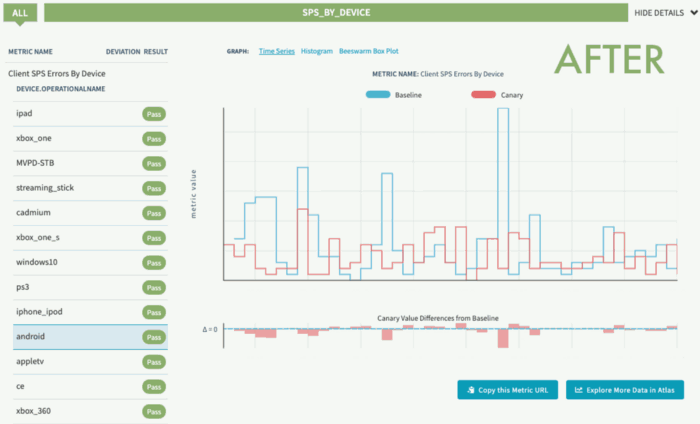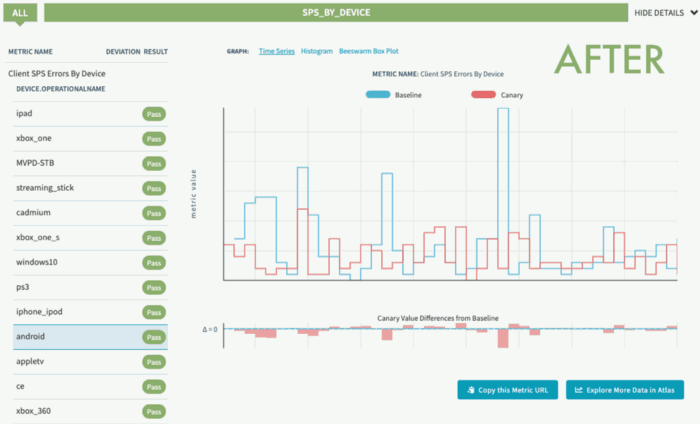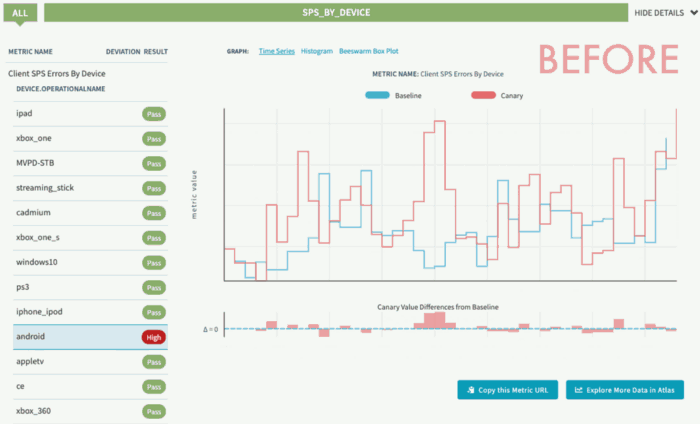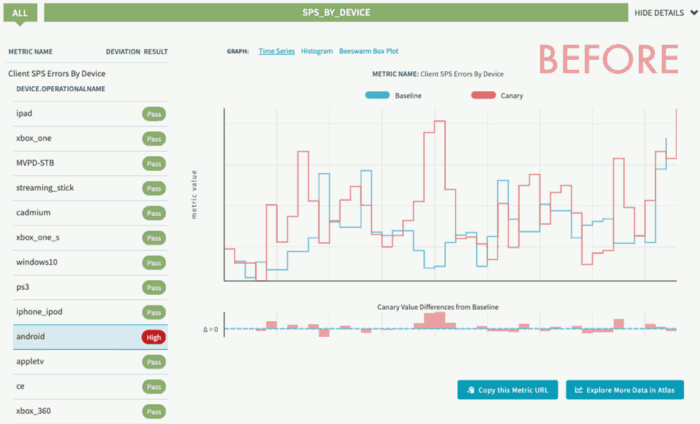
FIX前后实验数据回归检测(SPS表示流媒体的可用性)
2019年那时候,我们的逐步负载分流法还没有到位,Netflix的流媒体服务就经历过服务宕机的事件,导致相当大一部分比例的会员制一段时间都没法播放玩游戏。但到了2020年,我们的实现刚刚部署几天之后,团队就开始看到这种解决方案的好处了。当时Netflix也出现了类似的问题,其构成的潜在影响跟2019年的那次中断是一样的。但跟那时不同的是,Zuul的逐步流量卸载开始慢慢转移流量,直到服务处于健康状态,而这个过程中会员的播放能力一点都没受影响。
从下图可以看出,在发生事件期间,当Zuul在根据请求优先级执行逐步的流量卸载时,反映流媒体播放稳定性的每秒可用性指标(SPS)的情况。图中的不同颜色表示不同优先级请求被限制的情况。

这样,当基础设施一边从系统故障中自动恢复时,会员们仍能高兴地在Netflix上观看自己喜欢的节目。
至于未来,我们的团队正在考虑把请求优先级的运用扩展到其他用例上面,比方说设备和后端之间更好的重试策略,动态更改卸载阈值,利用混沌测试作为指导原则来调整请求优先级,以及其他能让Netflix更具弹性的领域。
如果你对帮助Netflix应对不断变化的系统和意外故障感兴趣的话,请与我们联系。我们正在招聘!
译者:boxi。
该文章来源互联网,如有侵权请联系删除
- 上一篇: 日赚4亿,腾讯为何成最赚钱互联网公司?
- 下一篇: B站大力难出奇迹
相关文章
- 国家卫健委等10部门:推进儿童医疗卫生服务高质量发展
- 冬天里的一把火,照出别样的东北
- 文旅新探|哈尔滨:2024的北国情书
- 一图速览|2024年纪检监察工作八大任务
- 微视频 | 制胜之道
- 星火成炬 | 以冰雪之名
- 年轻人三大“脆皮”症状:记忆力下降、情绪差、免疫力下降
- 春运期间,这些人可提前购票!购票指南→
- 万千气象丨他竟然把八九千年前老祖宗用的乐器复原出来了
- 铁路新年调图,“图”的是啥?
相关图集
- 黄河河曲段进入大面积流凌期 防凌工作全面启动
- 1至11月国家铁路发送货物37.27亿吨
- 全国研考工作准备就绪 @广大考生:教育部发布最新提醒
- 突破1亿千瓦 四川水电装机规模创新纪录
- 1至11月我国电子商务持续激发消费活力
- 又一水电站建成投产 四川水电装机容量突破1亿千瓦
- 新进展+1 京港高铁雄商段正线铺轨完成
- 黑龙江发布暴雪红色预警 局地将出现超20毫米降雪
热门推荐
- 八卦娱乐
- 网络焦点
- 幽默搞笑
- 美女明星
热门图片
更多阅读
- 今上午10点,济南餐饮消费券,开抢了,能减这么多
- 零点立交转向匝道拆除接近尾声
- 三角楼打翻 星空调色盘
- 科技助农 土地托管 一路麦香,这就是丰收的味道!
- 全国大部气温先升后降 中东部大范围雨雪上线
- “假一赔三给4双” 一些电商知假售假为何理直气壮
- 热门款不发货、退款无渠道……盲盒消费套路深?
- 2021年我国手机上网人数为10.29亿人
- 欺骗性收费、花式营销,云算命呼唤云监管
- 广西一女子被多名女子群殴拖行 被三女子按倒暴打拖行
- 待宰水牛发狂冲进餐馆顶飞男子 该男子被突如其来水牛顶伤
- 不可思议!天津高速鸵鸟奔跑车辆纷纷避让 车流中飞奔
- 货车车头冲出悬崖公路悬空 导航走近路,庞大车体进退两难
- 真的吗?警方通报男子开车撞妻子岳母 一个恍惚错将油门当刹车?
- 热点新闻
- 大话社区
- 图片报道
- 1黄河河曲段进入大面积流凌期 防凌工作全面启动
- 21至11月国家铁路发送货物37.27亿吨
- 3全国研考工作准备就绪 @广大考生:教育部发布最新提醒
- 4突破1亿千瓦 四川水电装机规模创新纪录
- 51至11月我国电子商务持续激发消费活力
- 6又一水电站建成投产 四川水电装机容量突破1亿千瓦
- 7新进展+1 京港高铁雄商段正线铺轨完成
- 8黑龙江发布暴雪红色预警 局地将出现超20毫米降雪
- 9打造超级水电工程集群 这里将清洁能源送达全国
- 10明日起 黄河壶口瀑布旅游区限时免门票
- 11世界在建最长高铁桥梁进度刷新 跨京杭运河斜拉桥顺利合龙
- 12国家水网重要组成部分引汉济渭二期工程北干线今日贯通
- 13无人机送货20分钟抵达 低空试飞解锁琼州海峡物流新场景
- 14迈出关键一步!全球航司首台C919飞行模拟机启用
- 1今上午10点,济南餐饮消费券,开抢了,能减这么多
- 2零点立交转向匝道拆除接近尾声
- 3三角楼打翻 星空调色盘
- 4科技助农 土地托管 一路麦香,这就是丰收的味道!
- 5全国大部气温先升后降 中东部大范围雨雪上线
- 6“假一赔三给4双” 一些电商知假售假为何理直气壮
- 7热门款不发货、退款无渠道……盲盒消费套路深?
- 82021年我国手机上网人数为10.29亿人
- 9欺骗性收费、花式营销,云算命呼唤云监管
- 10广西一女子被多名女子群殴拖行 被三女子按倒暴打拖行
- 11待宰水牛发狂冲进餐馆顶飞男子 该男子被突如其来水牛顶伤
- 12不可思议!天津高速鸵鸟奔跑车辆纷纷避让 车流中飞奔
- 13货车车头冲出悬崖公路悬空 导航走近路,庞大车体进退两难
- 14真的吗?警方通报男子开车撞妻子岳母 一个恍惚错将油门当刹车?