最近,在「AI画画」这一块,大厂们又卷上了新高度!
4月,在GPT-3大模型的加持下,Open AI对画图界的扛把子DALL-E进行了2.0版的全面升级。
让自然语言生成图像达到了全新的高度。比如下面这幅「孙子玩儿电脑」(非骂街)。

5月,谷歌不甘落后推出AI创作神器Imagen,效果奇佳。
号称重夺AI画画老大哥地位的Imagen,迅速被国外网友玩出了新高度,一波「虎戴VR」热度直接起飞。

有人惊呼,现在的新模型的保质期只有一个月了么?
谷歌一看,这是要开卷的节奏,不如我再进一步,再搞个新的AI大画家吧。
于是,只过了一个月,新一代AI绘画大师Parti就来了!

Parti,全名叫「Pathways Autoregressive Text-to-Image」,是谷歌大脑老大Jeff Dean提出的多任务AI大模型蓝图Pathway的一部分。
Jeff Dean在社交媒体上第一时间推广了一波。

同时他也表示,和一个月之前的「老前辈」Imagen相比,这次的Parti使用的是不同的技术路线。
为此,谷歌AI专门写了一篇博客文章,对比了两个「AI大画家」在技术层面上的区别。
虽然Imagen和Parti使用类似技术,不过但具体的策略是不同的——自回归和扩散。这样互补的方式使得两个强大模型的有了更加令人期待的组合!
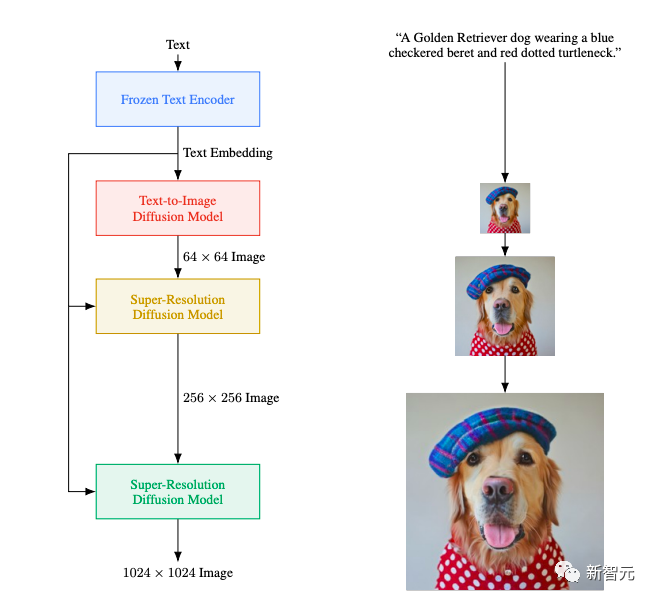
先来回顾一下「老前辈」Imagen,它是一个Diffusion模型,学习将随机点的图案转换为图像。
这些图像首先以低分辨率开始,然后通过超分辨率技术,不断的丰富图像的信息,进而达到提高图像分辨率的目的。
具体点讲,就是:
在用户输入文本后,如「一只戴着蓝色格子贝雷帽、穿着红色波点高领毛衣的金毛犬」,Imagen先使用一个冻结(frozen)T5-XXL 编码器将输入文本映射到嵌入序列和64×64图像扩散模型,再将生成的64×64图像上采样为256 × 256图像,最后上采样为1024 × 1024图像。
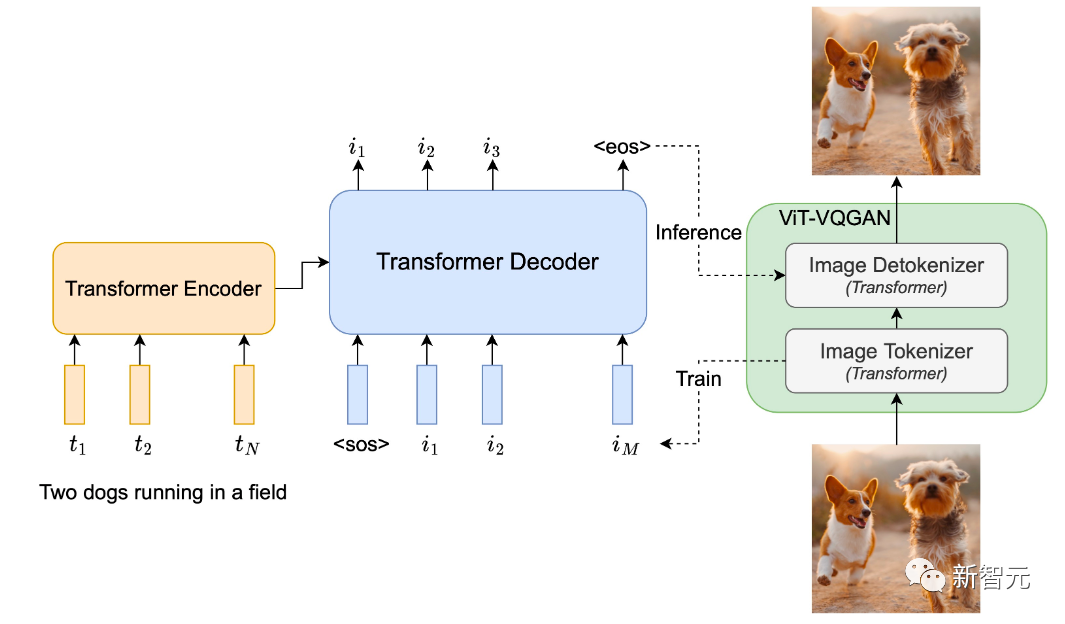
而这次新推出Parti是一个自回归模型,它的方法首先将一组图像转换为一系列代码条目,类似于拼图。然后将给定的文本提示转换为这些代码条目并「拼成」一个新图像。
换言之,Parti将「文本到图像的生成」转换成一个「序列到序列」的建模问题,类似于机器翻译——这使得它能够受益于大型语言模型(如PaLM),这对于处理长而复杂的文本提示和生成高质量的图像至关重要。
在这种情况下,目标输出是图像token的序列,而不是另一种语言的文本token。
Parti通过使用功能强大的图像标记器「ViT-VQGAN」将图像编码为离散token序列,并利用其重建图像token序列的能力,使其成为高质量、视觉多样化的图像。
Parti的模型规模支持扩展,最高可扩展至200亿参数。
参数越多,模型规模越大,生成图像的细节越丰富,错误信息也明显降低。
比如面对同样的文本输入:
身穿橙色连帽衫和蓝色太阳镜的袋鼠站在悉尼歌剧院前的草地上,胸前举着写着「欢迎朋友」的标语

在3.5亿参数下,袋鼠的眼镜不是蓝色,而且PS痕迹明显,背景只体现出「草地」,悉尼歌剧院基本看不出来。举的牌子上更不知道是哪国文字。
到了7.5亿参数下,眼镜颜色和背景都和文字准确对上了,但却多了另一只带着蓝眼镜的袋鼠。
扩展到30亿参数,之前的袋鼠不见了,但举的牌子多了一块,上面的字仍有拼写错误,但大概能看出是「欢迎朋友」了。但背景中的悉尼歌剧院似乎开了「影分身」。
最终在200亿参数下,文字中的内容得到准确再现。
换一张图,也是如此。文本信息细节越少,体现的越明显。
比如文本是「小提琴的背面」这几个字:

直到30亿参数下,生成的图像仍然是「小提琴的正面」,直到200亿参数下,才生成了正确的图像。
多面手「艺术家」,风格百搭
除了由模型参数量扩大带来的细节提升外,画画最要紧的是能画出不同风格,要都是千篇一律,那还叫艺术家吗?
Parti表示,这挺简单的。
比如命题作画:
一只浣熊穿正装,头戴礼帽,拄着拐杖,拿着个垃圾袋。
就能画出梵高风格的:

埃及法老风格的:

甚至是像素艺术风的:

再比如下面的文字:
「一只老虎戴着列车长的帽子,手里拿着一块滑板,上面有一个阴阳符号。」
也可以画成油画风,真真的那种 。

或者版画风,酷酷的那种。

甚至国画风,萌萌的那种。

当然,也有翻车的时候。
比如下面这个作品,文字是「一个没有香蕉的盘子,旁边有一个没有橙汁的玻璃杯。」

然而,生成的图片中盘子里全是香蕉,玻璃杯里也几乎盛满了橙汁!
就当是艺术家偶尔打了个盹吧!
看起来,以后「斗图界」说不定可以告别表情包了,想要什么图,打字就行了!
早些年要是能有这样的神器,「美术课恐惧症」的小编可能也会免去不少不堪回首的回忆吧。
参考资料:
https://parti.research.google/
https://blog.google/technology/research/how-ai-creates-photorealistic-images-from-text/
本文来自微信公众号“新智元”(ID:AI_era),编辑:David 如願 好困,36氪经授权发布。
该文章来源互联网,如有侵权请联系删除
相关文章
- 国家卫健委等10部门:推进儿童医疗卫生服务高质量发展
- 冬天里的一把火,照出别样的东北
- 文旅新探|哈尔滨:2024的北国情书
- 一图速览|2024年纪检监察工作八大任务
- 微视频 | 制胜之道
- 星火成炬 | 以冰雪之名
- 年轻人三大“脆皮”症状:记忆力下降、情绪差、免疫力下降
- 春运期间,这些人可提前购票!购票指南→
- 万千气象丨他竟然把八九千年前老祖宗用的乐器复原出来了
- 铁路新年调图,“图”的是啥?
相关图集
- 2026年春运首日琼州海峡过海旅客近10万人次 同比增长50.7%
- 家电及数码和智能产品补贴政策全面落地 1月补贴超1500万台
- 线路上新、轻装出行、网络订票 今年春运之旅更便捷
- 油价上调!加满1箱油将多花8元
- 今年春节“消费大礼包”有哪些内容?“乐购新春”活动来了
- 造型多样、花色“出彩”……各地年宵花争奇斗艳
- 多地优化购房政策,能否释放住房消费潜力?
- “新国补”落地首月全国家电、数码和智能产品补贴超1500万台
热门推荐
- 奇闻异事
- 离奇事件
- 幽默搞笑
- 考古发现




热门图片
更多阅读
- 这座三峡之巅的康养小镇 让我们乐不思“暑”
- 中国五十名山之一,坐落在江苏省,海拔最高只有142米
- 成都“小桂林”走红:竹筏泛舟,星空露营,冷门又省钱!
- 云南昆明晋宁观光小火车,链接现实和童话的梦幻之车
- 1元可以干啥?直升机飞行体验了解一下!
- 生态绿洲洼地起 千亩荒滩换新颜——大荔县全……
- 河南淮阳古城,伏羲定都之地,膜拜4600年前的城市排水系统
- 合肥最美的乡村公路,走过那里的人一看就喜欢,太美了
- 陕西又一古镇走红,人称安康“小江南”,却以“香柏岩”媲美华山
- 巴厘岛每天共接待2000至2500名本土游客
- 【2020平凉崆峒文化旅游节】平凉就这么漂亮
- 四川又一公园走红,人称德阳“吴哥窟”,1080米的石墙撑起现代艺术
- 大量邮轮停泊在海上无处可去,有人却脑洞大开,拿她们做起了生意……
- 等一个人,陪我去看川西的沟
- 热点新闻
- 大话社区
- 图片报道
- 12026年春运首日琼州海峡过海旅客近10万人次 同比增长50.7%
- 2家电及数码和智能产品补贴政策全面落地 1月补贴超1500万台
- 3线路上新、轻装出行、网络订票 今年春运之旅更便捷
- 4油价上调!加满1箱油将多花8元
- 5今年春节“消费大礼包”有哪些内容?“乐购新春”活动来了
- 6造型多样、花色“出彩”……各地年宵花争奇斗艳
- 7多地优化购房政策,能否释放住房消费潜力?
- 8“新国补”落地首月全国家电、数码和智能产品补贴超1500万台
- 92月2日春运首日全国铁路发送旅客1223.5万人次
- 10无人机和机器人首次写入中央一号文件
- 11“政策红包”能否释放住房消费潜力?专家:住房公积金的使用仍需进一步提高效率
- 12春运路上寒潮来袭 途经这些路段需注意
- 13航司增加运力、增设航线 C919国产大飞机也要投入春运
- 14千年花馍、春节“过油” 这些年俗小吃受欢迎
- 1今上午10点,济南餐饮消费券,开抢了,能减这么多
- 2零点立交转向匝道拆除接近尾声
- 3三角楼打翻 星空调色盘
- 4科技助农 土地托管 一路麦香,这就是丰收的味道!
- 5全国大部气温先升后降 中东部大范围雨雪上线
- 6“假一赔三给4双” 一些电商知假售假为何理直气壮
- 7热门款不发货、退款无渠道……盲盒消费套路深?
- 82021年我国手机上网人数为10.29亿人
- 9欺骗性收费、花式营销,云算命呼唤云监管
- 10广西一女子被多名女子群殴拖行 被三女子按倒暴打拖行
- 11待宰水牛发狂冲进餐馆顶飞男子 该男子被突如其来水牛顶伤
- 12不可思议!天津高速鸵鸟奔跑车辆纷纷避让 车流中飞奔
- 13货车车头冲出悬崖公路悬空 导航走近路,庞大车体进退两难
- 14真的吗?警方通报男子开车撞妻子岳母 一个恍惚错将油门当刹车?